Text: Medien.Daten
| Website: | OpenMoodle der Universität Bielefeld |
| Kurs: | Medienkompetenz für die digitale Welt. Ein praktischer Wegweiser |
| Buch: | Text: Medien.Daten |
| Gedruckt von: | Gast |
| Datum: | Donnerstag, 30. Juli 2026, 14:19 |
Inhaltsverzeichnis
- 1. Daten überall – Big Data
- 2. Was ist Künstliche Intelligenz (KI) und warum wird KI eingesetzt?
- 3. Anwendungsfelder von Künstlicher Intelligenz: Das Beispiel Pflege
- 4. Maschinelles Lernen
- 5. Algorithmen – Was sind Algorithmen und wofür brauchen wir sie?
- 6. Deep Learning als Teilbereich des Maschinellen Lernens
- 7. Anwendungsfelder von Deep Learning: Das Beispiel der Veränderung von Bildern
- 8. Anwendungsfelder von Deep Learning: Das Beispiel Sprachmodelle
- 9. Kritisches zu Chatbots
- 10. Ethische Aspekte und Gefahren von KI
- 11. Zwei Beispiele von Diskriminierung: Strafverfolgung und Bewerbungsprozesse
- 12. Ansätze gegen den Digital Bias
- 13. Gesetze zur Regulierung von Künstlicher Intelligenz
- 14. Social Media und Algorithmen: Das Beispiel TikTok
- 15. Wie kann man sich vor Manipulation durch Algorithmen schützen?
- 16. Datenkompetenz – Data Literacy
- 17. Kategorisierung von Datenkompetenz
- 18. Fazit
- 19. Verwendete Quellen
3.1 Daten überall – Big Data
Was wissen Sie bereits über Daten, Algorithmen und Künstliche Intelligenz? Welche weiteren Begriffe, die Sie kennen, verbinden Sie damit? In welchem Kontext werden bzw. sind diese für Sie relevant?
Durch die alltägliche Nutzung von Medien werden jeden Tag große Datenmengen produziert. Sei es, wenn wir bspw. bei Google oder einem anderen Anbieter eine Suche eingeben, online über einen Anbieter etwas einkaufen, eine Online-Zeitung lesen oder soziale Netzwerke nutzen, um mit unseren Freund*innen in Kontakt zu treten. Aber auch durch Reisebuchungen, Überwachungskameras oder Kundenkarten entstehen immer größere Datenmengen (vgl. Aust 2021). Die Massen an Daten und die Geschwindigkeit, mit der sie produziert werden, werden als Big Data bezeichnet. In der Literatur wird der Begriff Big Data häufig über die drei Kriterien Volume (Menge von Daten), Velocity (Geschwindigkeit der Erzeugung von Daten) und Variety (Vielfalt von Daten) erklärt (vgl. Aust 2021). Dabei müssen nicht zwangsläufig alle drei Merkmale vorhanden sein, um von Big Data zu sprechen. Auch werden in einigen Definitionen noch andere Merkmale herangezogen.
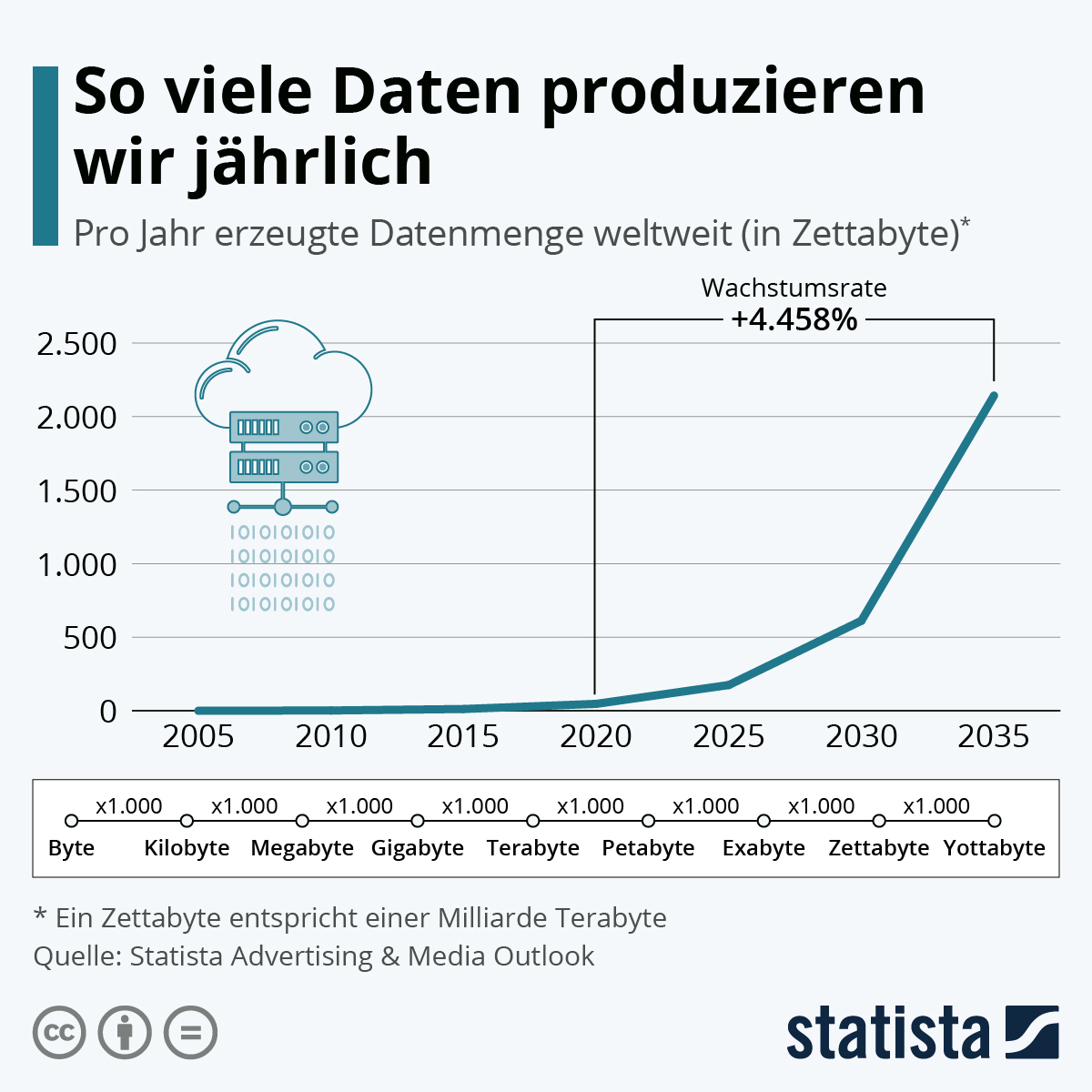
Abb. 3.1: Jährlicher Verbrauch produzierter Daten
Quelle: Statista, 2023
Die Verarbeitung dieser großen Datenmengen ist verhältnismäßig aufwendig. Ist die Qualität von Daten schlecht, können diese nicht weiterverwendet werden und müssen aussortiert werden. Auf Grund der Menge und vor allem der Vielfalt der Daten müssen sie in Datenbanken gespeichert werden, die eine entsprechende Leistungsfähigkeit besitzen. All das ist mit hohem Aufwand (u.a. durch den Platz, den große Datenbanken benötigen, und die Kosten, die sie verursachen) verbunden (vgl. Aust 2021). Dennoch haben Unternehmen trotz des erheblichen Aufwandes ein Interesse daran, möglichst viele Daten von Nutzer*innen zu sammeln und zu speichern. In den von Nutzer*innen preisgegebenen Daten stecken für Unternehmen viele wichtige Informationen. Anbieter wie Meta Platforms als Inhaber von Facebook und Instagram, Google usw. sammeln Daten, analysieren und verknüpfen sie und nutzen sie gegebenenfalls zu kommerziellen Zwecken. Aus diesen Daten resultiert ein personalisiertes Produkt, wie bspw. der Facebook Feed oder die TikTok Startseite, das entsprechend der Interessen von Nutzer*innen hergestellt wird. Besonders Social Media wären ohne die Big Data Techniken kaum denkbar. Bei besonders großen und globalen Unternehmen bedarf es hierfür besonders anspruchsvoller Datenverarbeitungstechniken (vgl. Aust 2021).
Auch Cookies sind Daten in Form von kleinen Textdateien, die lokal auf einem Rechner von Benutzer*innen durch das Besuchen einer Internetseite gespeichert werden. Bei einem erneuten Besuch auf einer Webseite werden die Textdateien (Cookies) mittels zufällig generierter Unique-Identifier (kurz IDs genannt) an einen Server gesendet (vgl. Kulyk et al. 2019). So werden Informationen durch einen Webserver auf einem Rechner von Benutzer*innen hinterlegt, wie bspw. Anmeldeinformationen, sodass bei einem erneuten Besuch der Internetseite die Angabe einer Information für eine Anmeldung (bspw. E-Mail-Adresse) übersprungen werden kann. Betreibende von Internetseiten haben durch Cookies die Möglichkeit, Informationen über die Benutzer*innen und das Nutzungsverhalten zu sammeln, um entsprechend bspw. Werbungen auf Nutzer*innen abzustimmen (vgl. Kulyk et al. 2019).
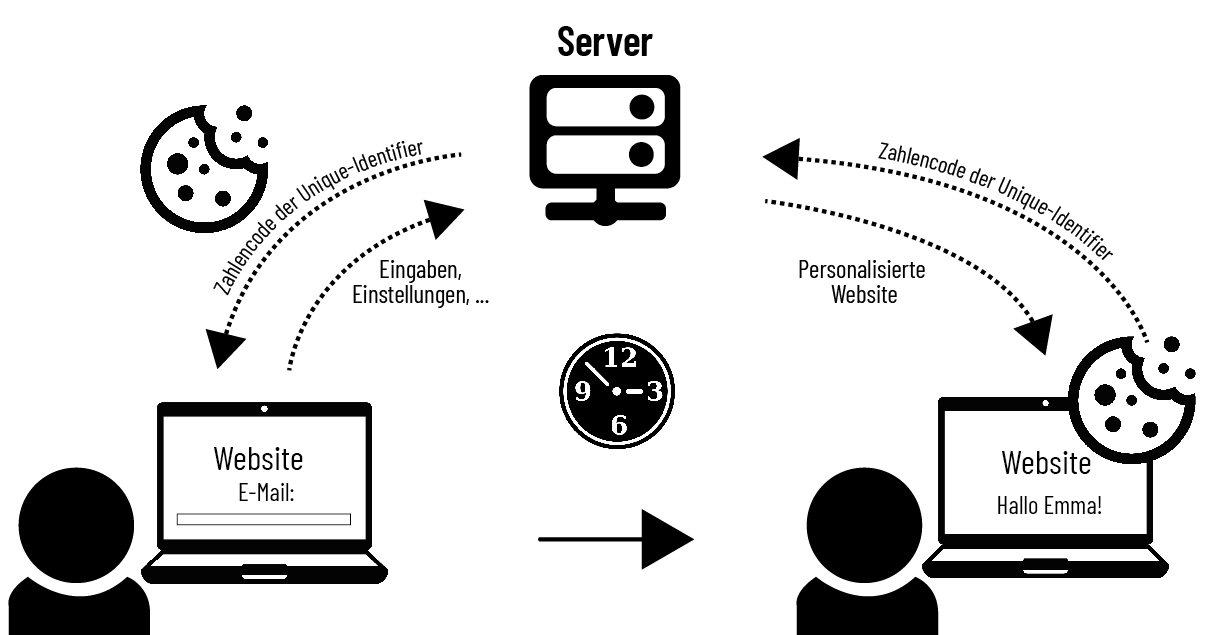
Abb. 3.2: Die Funktionsweisen von Cookies.
Quelle: Eigene Darstellung 2024.
Bspw. werden Nutzer*innen bei einer Online-Recherche nach Sportschuhen beim erneuten Aufrufen einer Webseite häufig weitere Angebote zu ähnlichen Sportschuhen angezeigt. Cookies können sowohl von Webseitenbetreibenden als auch von Werbefirmen auf einer Internetseite platziert werden. Dementsprechend unterscheidet man zwei verschiedene Arten von Cookies: Standard Cookies werden lediglich von Internetseitenbetreibenden gesetzt und nur sie können diese auch auslesen. Zusätzlich gibt es auch Drittanbieter Cookies. Jene können seitenübergreifend von Werbetreibenden auf diversen Internetseiten platziert und ausgelesen werden. Dadurch kann ein Unternehmen Cookies von allen Webseiten auslesen, auf denen diese Cookies platziert wurden, um so Nutzungsmuster von Nutzer*innen zu erhalten (vgl. Kulyk et al. 2019).
Wenn Sie sich jetzt fragen, wie Sie herausfinden können, wo und welche Daten von Ihnen gespeichert werden, stellt die Seite Privacy Check eine Suchmaschine vor, die Ihnen dabei hilft, die Nutzung Ihrer Daten nachzuvollziehen (https://www.experte.de/browser-privacy-check
Eine ähnliche Software wie Privacy Check, mit der man verdeckte Dienste (Übermittlung privater Daten an Seitenbetreibende) einsehen kann, stellt Ghostery dar (https://www.ghostery.com/
Für alle Internetseiten bleibt jedoch zu beachten: Programme ändern sich stetig und Verlinkungen werden neu gesetzt. Entsprechend sei Nutzer*innen geraten, regelmäßig nach aktuellen Programmen/Informationen zu schauen. Für einen sicheren Umgang in der Verwaltung von Cookies können Sie folgende Maßnahmen treffen:
- Sie können Cookies regelmäßig selbstständig löschen. Dafür gehen Sie in Ihrem Browser am Beispiel vom Firefox Browser auf: »Einstellungen«, »Datenschutz & Sicherheit«, »Cookies und Webseiten-Daten«, »Daten entfernen«. Wenn Sie dann auf »leeren« drücken, haben Sie die gespeicherten Cookies gelöscht.
- Sie können Cookies bereits vorab verwalten: Gehen Sie dazu erneut auf »Einstellungen«, dann auf »Datenschutz & Sicherheit«, »Cookies und Webseiten-Daten« und betätigen Sie das Häkchen bei »Cookies und Webseiten-Daten beim Beenden von Firefox löschen«. Dann werden Cookies immer automatisch gelöscht, wenn Sie eine Webseite schließen.
- Zusätzlich können Sie Drittanbieter (seitenübergreifende) Cookies ausstellen: Dazu gehen Sie erneut auf »Einstellungen«, dann auf »Datenschutz & Sicherheit« und unter dem Punkt »Browser-Datenschutz« aktivieren Sie die Einstellung »Benutzerdefiniert« und stellen dabei den Reiter »Cookies zur seitenübergreifenden Aktivitätenverfolgung« ein.
Der Begriff Big Data wird häufig verwendet, wenn die Kriterien der
- Menge an Daten,
- die Geschwindigkeit, mit der sie produziert werden
- und eine Vielfalt von Daten vorliegen.
Es gibt Programme, die Ihnen anzeigen, welche Daten Sie bei Ihrer Internetnutzung (potenziell) preisgeben.
Bearbeiten Sie die folgenden Aufgaben:
Reflektieren Sie Ihre eigenen Gedanken und Meinungen zu Big Data: Wie genau beeinflusst Big Data Ihre persönliche oder berufliche Lebenswelt? Welche Chancen und Risiken sehen Sie für sich persönlich?
3.2 Was ist Künstliche Intelligenz (KI) und warum wird KI eingesetzt?
Der Begriff der ›Künstlichen Intelligenz‹ (KI) entstammt aus dem Forschungsgebiet der Informatik und beschreibt die Tatsache, dass Computern die Fähigkeit übertragen wird, intelligente Entscheidungen selbst zu treffen, wie z.B. Übersetzungen, oder Dialoge mit Menschen durchzuführen. Dennoch gibt es bis heute keine feste Definition, die alle relevanten Aspekte der KI miteinschließt. Vielmehr wird der Begriff als Sammelbegriff für z.B. Expertensysteme (Programme, die Lösungen zu bestimmten Themen beitragen), Maschinelles Lernen, autonomes Fahren oder intelligente Assistenten verwendet (vgl. De Witt et al. 2020). Bei vielen Anwendungen ist es schwierig, eine Unterscheidung zu treffen, ob es sich schon um eine KI oder nur um eine Digitalisierung handelt. Eine Unterscheidung lässt sich aber deutlich treffen: Man kann in starke KI und schwache KI einteilen.
Schwache Künstliche Intelligenz kann klar abgegrenzte Aufgaben übernehmen, wie z.B. ein Bild zu erkennen, zu navigieren oder Schach zu spielen (vgl. Aust 2021). Hier können durch die Fortschritte der letzten Jahre Computer sogar Menschen übertreffen. Das weltbekannte Beispiel eines Computerprogramms namens ALPHAGO, das das japanische Brettspiel GO spielen kann, hat 2016 den weltbesten menschlichen GO-Spieler besiegt (vgl. Fjelland 2020).
Starke Künstliche Intelligenz umfasst Fähigkeiten, die dem menschlichen Denkvermögen ähneln, wie z.B. die Kompetenz, sich selbst Ziele zu setzen oder Wissen auf andere Bereiche zu übertragen. Sie verfügt damit sozusagen über ein »eigenes Bewusstsein«. Starke KI gibt es allerdings bis heute noch nicht und es bleibt aus wissenschaftlicher Perspektive unklar, ob es diese Form je geben wird (vgl. De Witt et al. 2020). Ob eine KI ethisch vertretbare Entscheidungen treffen kann, ist unter Expert*innen noch umstritten.
KI wird bereits vielfältig in unterschiedlichen Bereichen und Kontexten (Unternehmen, Hochschulen, Schulen, Polizei usw.) eingesetzt. Sinn dieses Einsatzes ist vor allem, Prozesse zu optimieren und effektiver zu gestalten. Dies betrifft z.B. bestimmte Abläufe, wie die Vergabe von Studienplätzen an Hochschulen, den Bereich der Kriminalitätsarbeit bei der Polizei oder die Personalauswahl in Unternehmen (vgl. Horwarth 2022).
Die Geschichte über den weltbesten GO Spieler und die Bedeutung des Sieges der KI über den Spieler wird in folgendem Dokumentarfilm aufgezeigt:
- Google DeepMind (2020). AlphaGo - The Movie. Full award-winning documentary, YouTube, [Video] https://www.youtube.com/watch?v=WXuK6gekU1Y&ab_channel=GoogleDeepMind
Die deutsche Online-Plattform Lernende Systeme – Die Plattform für Künstliche Intelligenz stellt eine Auswahl an kostenlosen Online-Kursen bereit, in denen verschiedene Gebiete der KI in ihren Funktionsweisen und Einsatzbereichen getestet werden können. Eine Auswahl nationaler Kurse wird nachfolgend aufgezeigt (vgl. Mah et al. 2020):
- KI in der Wirtschaft: https://www.oncampus.de/weiterbildung/moocs/klooc-digitalisierung-mittelstand-im-wandel-3
- KI im Gesundheitswesen: https://open.hpi.de/courses/digitalhealth2020
- KI in der Bildung: https://ki-campus.org/courses/kischule2020
- Grundlagen KI: Paaß/Hecker (2020). Künstliche Intelligenz. Wiesbaden: Springer Vieweg. https://link.springer.com/book/10.1007/978-3-658-30211-5
. - Machine Learning Blog: https://machinelearning-blog.de/
3.3 Anwendungsfelder von Künstlicher Intelligenz: Das Beispiel Pflege
Nach der allgegenwärtigen Digitalisierung ist die Nutzung von Künstlicher Intelligenz bereits im Gesundheitswesen angekommen, so auch in der Pflege. Das hat zum Ziel, den Pflegeberuf innovativer und attraktiver zu machen, indem gewisse Tätigkeiten durch technische Neuerungen ersetzt werden. In einigen Klinken und Krankenhäusern werden bereits kleine Roboter verwendet (vgl. Irmler 2023). Sie werden u.a. eingesetzt, um Patient*innen Bewegungen zu zeigen, körperliche Übungen vorzuführen oder Gesellschaftsspiele wie Schach zu spielen. Um die Abläufe durchführen zu können, sind Roboter mit einer Künstlichen Intelligenz programmiert. Sie sind in der Lage, Personen voneinander zu unterscheiden. Für den Einsatz von Robotik und KI in der Gestaltung des Alltags und der Versorgung von gepflegten Personen hat sich der Begriff ›Geriatronik‹ (Irmler 2023: 45) herausgebildet. Das Ziel des Einsatzes von Robotern in der Pflege ist die Unterstützung des Personals. KI kann bisher kommunikative Aspekte, Empathie und emotionale Intelligenz des Pflegepersonals nicht ersetzen.
Neben Robotern stellen moderne Dokumentationssysteme ein Einsatzgebiet von KI in der Pflege dar. Dokumentationssysteme sind Softwareprogramme, die das Personal bei der Lösung von Problemen unterstützen sollen. Die Unterstützung wird durch die Software geleistet, indem die KI Daten der Patient*innen analysiert und Handlungsempfehlungen auf Basis der eingegebenen Informationen (Daten) des Personals ausspricht. Zusätzlich sind die Dokumentationsprozesse automatisiert, sodass ein erheblicher Zeitaufwand bei der Dokumentation von Informationen gespart werden kann. Zudem können die Systeme präventive Maßnahmen vorhersagen und Vorschläge zur Behandlung vornehmen, sodass pflegerische Interventionen umgesetzt werden können (vgl. Mania 2021). In den letzten Jahren hat im Kontext der Künstlichen Intelligenz das maschinelle Lernen einen hohen Stellenwert erhalten. Das Maschinelle Lernen, das eine Form der Künstlichen Intelligenz darstellt, wird von Expert*innen als eine der wichtigsten Basistechnologien dieses Zeitalters beschrieben (vgl. Buxmann/Schmidt 2021).
Versetzen Sie sich in die Lage, gepflegt zu werden und dabei durch einen Roboter unterstützt zu werden. Hätten Sie dabei Bedenken oder wären Sie dem Roboter gegenüber gänzlich aufgeschlossen? Welche Vor- und Nachteile würden Sie für sich persönlich sehen?
3.4 Maschinelles Lernen
Das Maschinelle Lernen wird als Teilgebiet von Künstlicher Intelligenz und häufig als Sammelbegriff für unterschiedliche statistische Analysemethoden verwendet. Das maschinelle Lernen beschreibt Verfahren zur Erkennung von Korrelationen
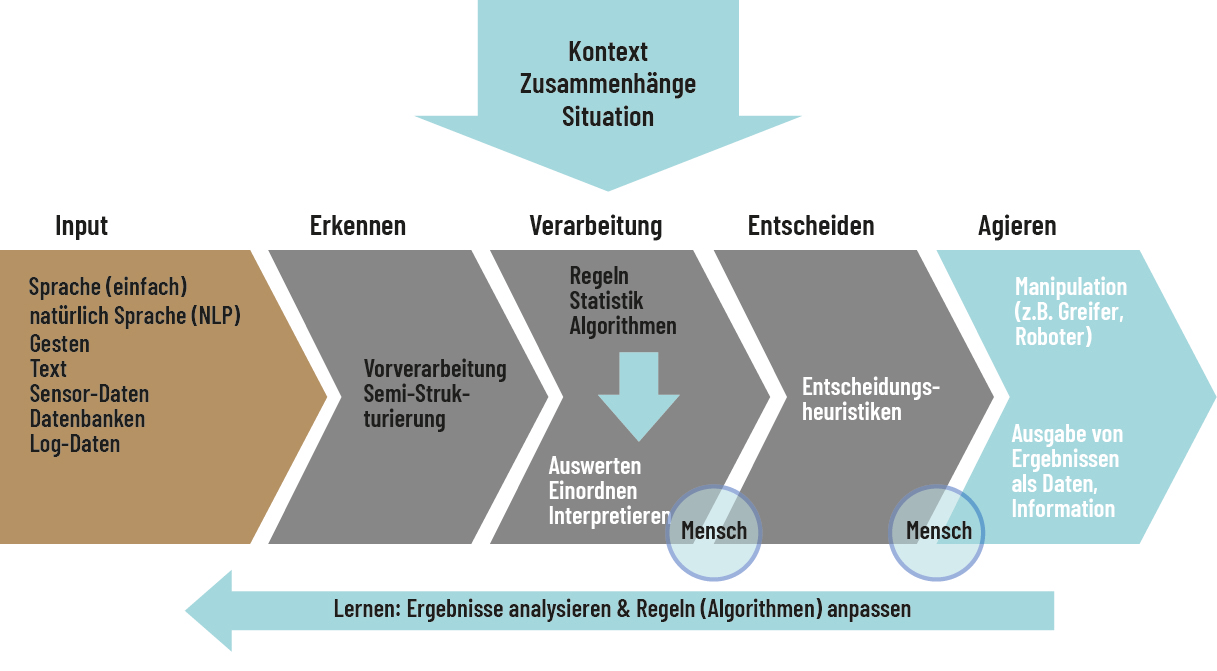
Abb. 3.3: Der Mensch als Teil des Systems im Maschinellen Lernen.
Quelle: Eigene Darstellung angelehnt an Mockenhaupt/Schlagenhauf 2024.
3.5 Algorithmen – Was sind Algorithmen und wofür brauchen wir sie?
Algorithmen sind Werkzeuge, um mathematische Rechenprobleme zu lösen, die auf Grund der großen Datenmengen entstehen. Sie helfen nicht nur bei der Datenverarbeitung für Maschinelles Lernen, sondern sie lernen stetig weiter und programmieren sich selbst, ohne dass weitere technische Eingriffe durch den Menschen nötig werden (vgl. Hummel 2017). Am Beispiel der Gesichtserkennung lässt sich das wie folgt veranschaulichen: Algorithmen lernen eigenständig, Muster zu erkennen, die für ihre Suche nützlich sind. Hierfür verwendet eine Software viele Muster wie bspw. die Position der Augen, die Größe einer Nase, die Wangenknochenform und weitere markante Stellen eines Gesichtes. Um ein bestimmtes Gesicht mit Hilfe einer Software erkennen zu können, werden Vektoren zweier Bilder verglichen. Ein Bild hat ein Raster mit einer großen Anzahl an Pixeln und bestimmten Grauwerten. Daraus ergibt sich ein Datensatz mit einer bestimmten Dimension, die mathematisch als Vektor bezeichnet wird (vgl. Hummel 2017). Die Gesichtserkennung kann für viele gute Zwecke eingesetzt werden, wie bspw. für die Bekämpfung von Verbrechen. Dennoch bringt das Thema auch kritische Aspekte mit sich, wie die Begrenzung von Privatheit.
Es gibt unterschiedliche Algorithmen, die sich in die drei Modelle des Überwachten Lernens, des Unüberwachten Lernens und des Bestärkenden Lernens für Maschinelles Lernen einteilen lassen (vgl. Aust 2021):
Das Überwachte Lernen (Supervised Learning) beschreibt einen Algorithmus, bei dem anhand von vorhandenen Daten Informationen gelernt werden. Es wird also konkret nach einer definierten Zielvariable gesucht. So kann der Algorithmus bspw. lernen, ob auf einem Bild eine Katze abgebildet ist oder ob es sich nicht um eine Katze handelt. Dazu wird der Algorithmus mit großen Mengen an Bildern in Form eines Sets an Daten »gefüttert«, indem Bilder in rechnerische Variablen umgewandelt werden, auf denen Katzen zu erkennen sind. Der Algorithmus lernt die Merkmale einer Katze kennen und kann dann anhand dieses Sets an Daten erkennen: Katze ja oder Katze nein (vgl. Aust 2021). Der Mensch überprüft schließlich das Ergebnis und wenn der Algorithmus die richtige Entscheidung getroffen hat, wird das Ergebnis zum Standard ernannt (vgl. Mockenhaupt/Schlagenhauf 2024).
Bei dem Algorithmus des Unüberwachten Lernens (Unsupervised Learning) verhält es sich anders. Hier wird nicht nach einer gelernten Zielvariable gesucht (Katze ja/Katze nein), da das Suchergebnis nicht genau als richtig oder falsch definiert ist. Vielmehr sucht der Algorithmus eigenständig nach Strukturen in den vorhandenen Daten. Wenn bspw. ein Unternehmen anhand eines Online-Shops das Kaufverhalten von Kund*innen durch Typenbildung analysieren möchte, teilt der Algorithmus das Verhalten eigenständig in Typengruppen ein (vgl. Aust 2021). Das Entscheidungsverhalten wird dabei nicht von Menschen kontrolliert, sondern das System handelt autonom (vgl. Mockenhaupt/Schlagenhauf 2024).
Die Algorithmen des Bestärkenden Lernens (Reinforcement Learning) werden eingesetzt, um Entscheidungen eigenständig zu treffen. Hier hat der Algorithmus vorab keine Informationen in Form von Daten. Der Algorithmus lernt durch die Durchführung von bestimmten Aktionen und wird durch die Rückmeldung (Feedback) von der Simulationsumgebung verbessert. Anders als beim überwachten Lernen, bei dem das System mit richtigen Ergebnissen gefüttert wird, werden im Bestärkenden Lernen nur Impulse in Form von Belohnungen gesetzt (vgl. Aust 2021). Am deutlichsten lässt sich dies am Beispiel von Spielen verdeutlichen, anhand derer die Algorithmen auch häufig beforscht werden. So kann ein Algorithmus bspw. Schach lernen, indem er gegen sich selbst spielt und durch richtige Züge belohnt wird. Für die Belohnung wird ein ähnliches Prinzip wie bei Menschen durch Programmierende angesetzt. Dabei wird die extrinsische Motivation (also durch äußere Reize und nicht durch eine innere, von sich selbst kommende Motivation) verwendet. Eine Software erhält beim Trainieren bzw. Lernen Punkte, wenn die Aufgabe erfüllt wurde. Wurde sie nicht korrekt erfüllt, erhält die Software Abzüge von Punkten. So lernt sie anhand von Punkten (Belohnung), stetig besser zu werden (vgl. Aust 2021).
Ein kurzes Erklärvideo zu Algorithmen, in dem die wichtigsten Grundlagen in drei Minuten erklärt werden, kann unter folgendem Link abgerufen werden:
- youknow (2019). Algorithmen in drei Minuten erklärt, YouTube, [Video] https://www.youtube.com/watch?v=FBUoEumkP2w
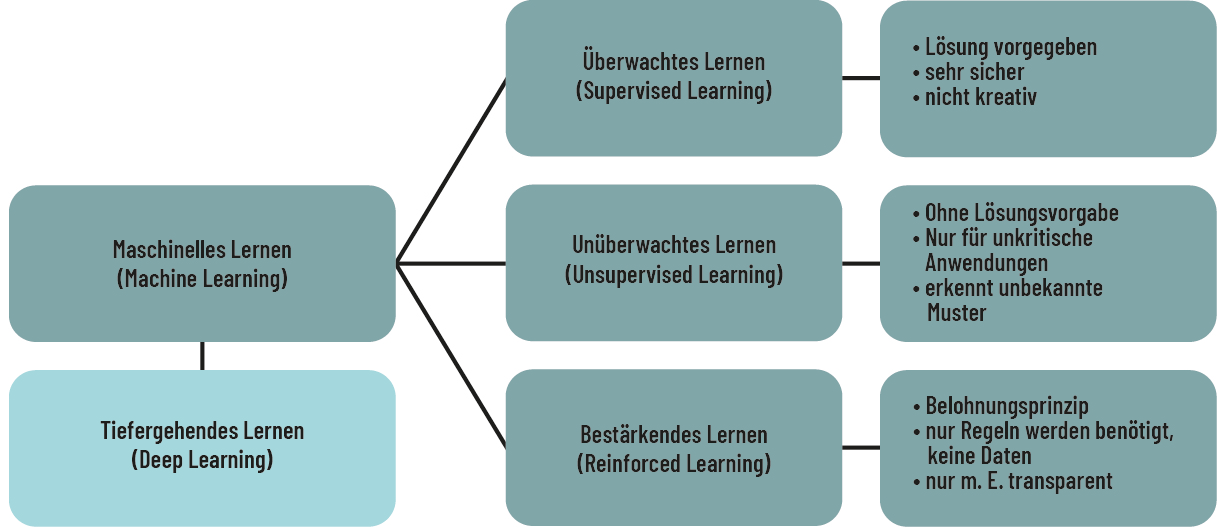 Abb. 3.4: Das Überwachte, Unüberwachte und Bestärkende Lernen des Maschinellen Lernens.
Abb. 3.4: Das Überwachte, Unüberwachte und Bestärkende Lernen des Maschinellen Lernens.
Quelle: Eigene Darstellung angelehnt an Mockenhaupt/Schlagenhauf, 2024.
3.6 Deep Learning als Teilbereich des Maschinellen Lernens
Deep Learning stellt eine Methode zur Informationsverarbeitung dar und zählt zu den Teilbereichen des Maschinellen Lernens und Künstlicher Intelligenz.
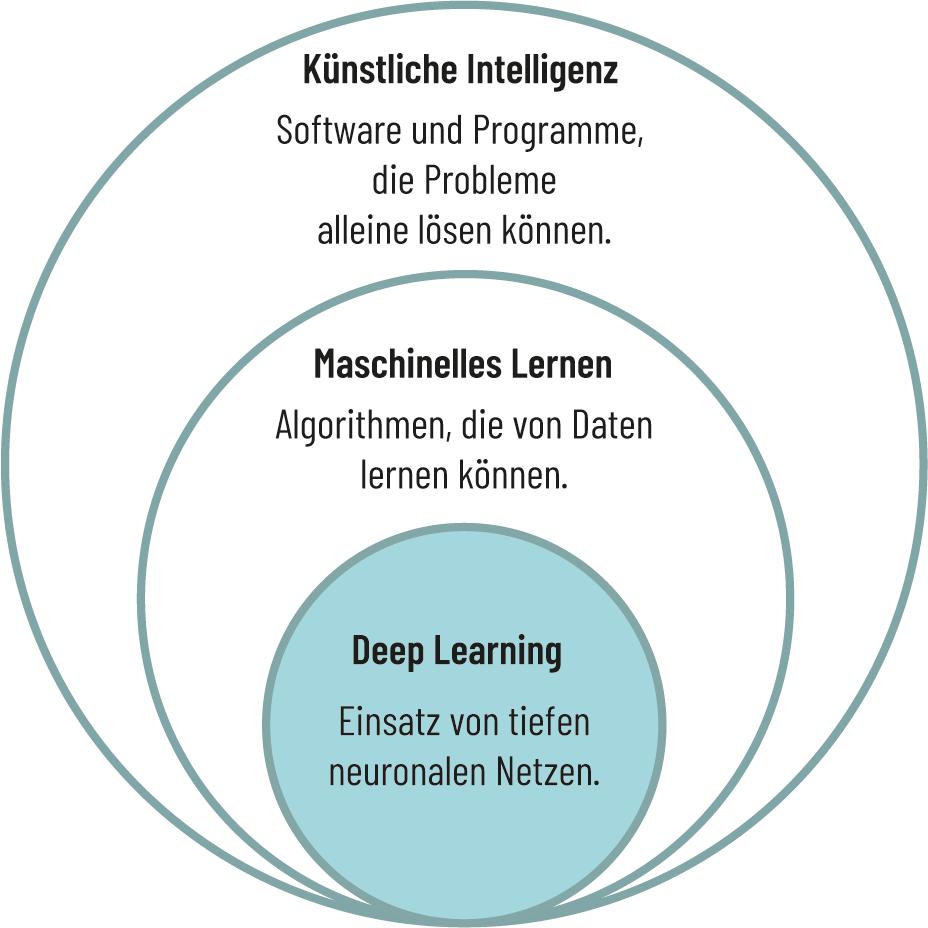
Abb. 3.5: Deep Learning als Teilbereich des Maschinellen Lernens.
Quelle: Eigene Darstellung angelehnt an datasolut 2023.
Das Deep Learning verwendet künstliche neuronale Netzwerke für die Analyse großer Datenmengen, die ähnlich wie unser Gehirn aus Erfahrungen lernen. Diese neuronalen Netzwerke stellen Algorithmen dar, die nach einer ähnlichen Struktur wie ein Gehirn aufgebaut werden (vgl. Aust 2021). Diese Methode der Informationsverarbeitung ermöglicht es einem System, eigene Entscheidungen zu treffen. Dazu muss ein Deep-Learning-Algorithmus, wie andere Algorithmen, zunächst entsprechend trainiert werden. Die Deep-Learning-Algorithmen können im Zuge einer erneuten Überprüfung anschließend noch einmal bestätigt oder geändert werden. Der Unterschied der Deep-Learning-Algorithmen im Vergleich zu den Algorithmen des Maschinellen Lernens liegt darin, dass die Deep-Learning-Algorithmen durch die Verwendung der neuronalen Netzwerke auch in unstrukturierten Informationen (Texte, Bilder, Töne usw.) Merkmale erkennen und numerische Werte zuordnen können. Anhand dieser Mustererkennung können die Algorithmen weiterarbeiten und weiterlernen (vgl. Aust 2021).
Algorithmen des Maschinellen Lernens hingegen nutzen keine neuronalen Netzwerke und können damit unstrukturierte Daten nicht sinnvoll weiterverarbeiten. Sie benötigen strukturierte Informationen, z.B. Werte aus einer Excel-Tabelle oder Datensätze einer Datenbank. Würde man dem Algorithmus des Maschinellen Lernens Katzenbilder präsentieren, müssten vorab spezifische Merkmale (Gesichtsform, Ohren, Farbe usw.) definiert werden. D.h., dass keine einfachen Bilder zur Datenverarbeitung genutzt werden können, sondern ein aufwendiges Feature Engineering (ein Prozess, in dem Rohdaten in Merkmale umgewandelt werden) durch den Menschen, wie am Beispiel der Katzenbilder erklärt, eingegeben werden müsste (vgl. Aust 2021). Die Algorithmen des Deep Learning hingegen benötigen diesen aufwendigen Prozess der Merkmalszuordnung vorab nicht. Sie können bei den Katzenbildern bspw. eigenständig Merkmale erkennen und zuordnen. Somit müssen diese Algorithmen zwar auch angelernt werden, aber weitaus weniger aufwendig. Das neuronale Netzwerk des Deep Learning arbeitet auf verschiedenen Ebenen. Am Beispiel der Bilderkennung lässt es sich wie folgt veranschaulichen: Ebene 1 erkennt die Helligkeit der einzelnen Pixel (Bildpunkte). Ebene 2 erkennt als Linie zusammenhängende Pixel. Ebene 3 erkennt den Unterschied zwischen horizontalen, vertikalen und diagonalen Linien. Auf der letzten Ebene schließlich erkennt das System z.B. das Foto einer Straße, das auf Grund vieler ähnlicher Bilder in eine Kategorie sortiert werden kann (vgl. Jones 2014).

Abb. 3.6: Die Ebenen des neuronalen Netzwerkes des Deep Learning.
Quelle: © Jones, N.: Computer science: The learning machines. Nature 505, 2014; Einzelbilder: Andrew Ng, Stanford Artificial Intelligence Lab (Ausschnitt).
3.7 Anwendungsfelder von Deep Learning: Das Beispiel der Veränderung von Bildern
Der Begriff Deep Fake (auch deepfake) kommt aus dem Englischen und stellt eine Verknüpfung aus den Wörtern Deep (bezugnehmend auf Deep Learning; s.o.) und Fake (Fälschung) dar. Von einem Deep Fake spricht man, wenn Medieninhalte von Fotos, Audios und Videos mit Hilfe von Künstlicher Intelligenz verändert und so verfälscht werden, dass sie echt aussehen (vgl. Mustak et al. 2023). Im Bereich des Deep Fake kommt am häufigsten das sogenannte Face Swapping zum Einsatz. Unter Face Swapping versteht man das Ersetzen einer Person auf einem Bild oder in einem Video durch das Gesicht einer anderen Person. Im öffentlichen Raum hat die Anwendung des Face Swapping bereits zu großen Diskussionen geführt, da dies gewisse Gefahren birgt. Ein bekanntes Beispiel ist ein Deep-Fake-Video von Barack Obama aus dem Jahr 2018, in welchem er Donald Trump vermeintlich beleidigt (vgl. Kaur et al. 2020). Daran wird deutlich, dass bspw. in politischen Kontexten eine Irreführung von tatsächlichen Ereignissen in Bildern und Videos möglich ist.
Welches Ausmaß und Folgen die Manipulation an Videos (deepfakes) nehmen kann wird in einem kurzen Dokumentarfilm des ZDF erläutert:
- Deepfakes – der Manipulation ausgeliefert? (2021). ZDF, [Video] https://www.zdf.de/wissen/leschs-kosmos/deepfakes-der-manipulation-ausgeliefert-100.html
3.8 Anwendungsfelder von Deep Learning: Das Beispiel Sprachmodelle
Wenn man sich mit Programmen der Spracherkennung, der Übersetzung von Texten oder der Generierung von Texten befasst, bewegt man sich im Feld der großen Sprachmodelle. Diese bezeichnet man im Englischen als Large Language Models oder kurz LLMs. Große Sprachmodelle basieren auf Deep-Learning-Algorithmen und werden auf Basis enorm großer Datenmengen trainiert. Die LLMs zählen zu dem Forschungsfeld, dass sich speziell mit der Entwicklung von Algorithmen des Natural Language Processing (NLP) befasst, sprich mit der Verarbeitung natürlicher Sprache. Große Aufmerksamkeit haben diese Modelle durch das bekannte Programm ChatGPT gewonnen (vgl. Fink 2023). Im November 2022 wurde der Chatbot ChatGPT veröffentlicht und damit der breiten Öffentlichkeit zur Verfügung gestellt. Der Chatbot wurde von OpenAI entwickelt und gilt mit seiner Technologie als ein fortschrittliches Sprachmodell. Die Idee von ChatGPT ist das Antworten auf von Nutzer*innen gestellte Fragen (sogenannten ›Prompts‹). Damit ChatGPT trainiert werden kann, um immer mehr neue Informationen zu lernen und wiedergeben zu können, wird eine große Menge an Textdaten in das Modell eingespeist, sodass es Beziehungen zwischen Wörtern und Sätzen erkennen lernt. Auf Grund der Größe der Textdaten kann der Chatbot Nuancen von Sprache lernen und entsprechend passende Antworten hervorbringen (vgl. Kalla/Smith 2023).
Neben ChatGPT gibt es noch weitere Chatbots, also Programme mit Künstlicher Intelligenz, um Unterhaltungen mit Menschen zu führen und auf Basis einer Unterhaltung zu lernen. Sie werden vielseitig als Kommunikationsmittel in Bereichen eingesetzt, in denen normalerweise Mitarbeitende eines Unternehmens als Ansprechpersonen dienen würden. Unternehmen setzen Chatbots vor allem aus Kostengründen ein, da dadurch Personalkosten in erheblichem Umfang gespart werden können. Gleichzeitig kann man auf diese Weise eine Rund-um-die-Uhr Betreuung gewährleisten (vgl. De Witt et al. 2020).
Es gibt zwei Funktionen von Chatbots. Die Einen sollen konkrete Aufgaben erledigen, für die sie programmiert wurden. So werden sie im Bereich der Hilfestellungen eingesetzt, wenn man als Kund*in Fragen technischer oder inhaltlicher Art hat, z.B. bei Bestellungen über einen Online-Shop (vgl. De Witt et al. 2020). Die andere Funktion dient der Unterhaltung. Chatbots unterhalten sich mittels Text oder Audio in menschenähnlicher Sprache. Sie können automatisierte Unterhaltungen durchführen, indem schnelle und präzise Antworten durch das System auf Nachfrage von Nutzer*innen gegeben werden können. Eine intuitive Nutzung wird durch die Nachahmung natürlicher Sprache gewährleistet. So kann ein Kundenservice verbessert werden, indem die Kundenzufriedenheit durch genauere Antworten gesteigert werden kann. Zudem werden Antworten personalisiert, indem sie den Interessen und Bedürfnissen der Nutzer*innen angepasst werden. Diese Anpassungsfähigkeit erlaubt es Unternehmen oder Organisationen, das System mit passenden Trainingsdaten zu versehen, um auf sie zugeschnittene Antworten für Nutzer*innen zu ermöglichen. Auch kann durch einen hohen Grad einer Skalierbarkeit (Größenveränderung) eine große Anzahl an Gesprächen gleichzeitig stattfinden. Dies bringt vor allem Vorteile für Bereiche mit sich, in denen viele Informationen parallel verarbeitet werden müssen (z.B. in großen Unternehmen).
Auch werden Chatbots zur Übersetzung von Sprache genutzt, was eine bedeutende Funktion für die globale Vernetzung darstellt (vgl. Kalla/Smith 2023). Dadurch, dass KI darauf ausgelegt ist, stetig weiterzulernen, ist eine zunehmende Verbesserung in den Antworten und der Sprache zu erwarten. Diese Übersetzungstechnik ist möglicherweise für Sie interessant, wenn Sie bspw. textbasierte Medien oder Audioaufnahmen für ein mehrsprachiges Publikum zugängig machen wollen. Ein Übersetzungsprogramm, das zuverlässig in verschiedene Sprachen übersetzen kann und dabei den Ansprüchen der DSGVO entspricht, ist DeepL (https://www.deepl.com/de/translator
3.9 Kritisches zu Chatbots
Bei der Nutzung gilt es jedoch stets zu beachten, dass Chatbots zwar als nützliches Werkzeug eingesetzt werden, aber meist keine perfekte Lösung präsentieren können. Chatbots sind in ihren Antworten bisher noch recht limitiert, da die Antworten aus einer vorgegebenen Menge an Antwortoptionen bestehen. Der Kontext eines umfangreichen Gesprächs kann bisher nicht verarbeitet werden, sodass es zu unpassenden Antworten kommen kann. Ebenfalls ist anzunehmen, dass Chatbots nicht auf Sarkasmus bzw. Humor reagieren können (vgl. Kalla/Smith 2023). Da Chatbots ihre Informationen aus Trainingsdaten erhalten, also von Menschen eingespeiste Datensätze (bspw. auf Plattformen wie Reddit etc.), ist anzunehmen, dass Informationen zu unterrepräsentierten Themen nicht dargestellt werden können. Die Qualität der Ergebnisse hängt somit stark von der Qualität der Trainingsdaten ab. Nutzer*innen sollten sich daher nicht einfach auf die Informationen und Formulierung von Chatbots im Allgemeinen und ChatGPT im Speziellen verlassen, sondern diese gewissenhaft nachprüfen und den Chatbot in Verbindung mit anderen Tools, Techniken und dem eigenen Knowhow verwenden (vgl. Ebd.).
Bearbeiten Sie die folgenden Aufgaben:
- Künstliche Intelligenz wird eingesetzt, um Prozesse effektiver zu gestalten und zu optimieren. Man unterscheidet in schwache KI und starke KI. Sie wird bereits vielfältig in unterschiedlichen Bereichen und Kontexten eingesetzt wie Unternehmen, Hochschulen, Schulen, Polizei usw. Sinn dieses Einsatzes ist vor allem, Prozesse zu optimieren und effektiver zu gestalten.
- Das Maschinelle Lernen wird als Teilgebiet von Künstlicher Intelligenz und häufig als Sammelbegriff für unterschiedliche statistische Analysemethoden verwendet. Das maschinelle Lernen beschreibt Verfahren zur Erkennung von Mustern innerhalb eines Datensatzes, um eigene Entscheidungen zu treffen. Da diese Datensätze meist große Datenmengen (Big Data) beinhalten, müssen sie in ihrer Komplexität mittels Algorithmen reduziert werden.
- Algorithmen sind Werkzeuge, um die Komplexität von großen Datenmengen zu reduzieren und sie nutzbar zu machen. Es gibt unterschiedliche Algorithmen: Die bekanntesten sind das Überwachte Lernen, das Unüberwachte Lernen und das Bestärkende Lernen. Algorithmen werden darauf trainiert, Muster in Datensätzen zu erkennen, Entscheidungen eigenständig zu treffen und sich weiter zu verbessern.
- Deep Learning zählt zu den Teilbereichen des maschinellen Lernens und Künstlicher Intelligenz. Das Deep Learning verwendet künstliche neuronale Netzwerke für die Analyse großer Datenmengen. Die Informationsverarbeitung ermöglicht es einem System, eigene Entscheidungen zu treffen. Die Deep-Learning-Algorithmen können durch die Verwendung der neuronalen Netzwerke auch in unstrukturierten Informationen Merkmale erkennen. Anwendungsfelder liegen u.a. im Bereich der Bild- und Spracherkennung und der Sprachmodelle. Diese Innovationen bergen jedoch auch Gefahren, indem Bilder verändert, Stimmen geklont werden und Sprachmodelle Vorurteile aufweisen können.
- Chatbots sind Programme mit Künstlicher Intelligenz, um z.B. Serviceleistungen, die sonst durch Menschen durchgeführt werden, zu ersetzen. Diese lernen aus Unterhaltungen mit Menschen, um Gespräche und z.B. Serviceleistungen stetig zu verbessern.
Unter folgenden Seiten können einige Chatbots ausprobiert werden:
- ELIZA (entwickelt von Jospeh Weizenbaum): https://www.masswerk.at/elizabot/
. - Mitsuku (entwickelt von Steve Worswick): https://www.pandorabots.com/mitsuku/
- Watson (entwickelt von IBM): https://www.ibm.com/products/text-to-speech
Um mehr Informationen zur Nutzung von ChatGPT und anderen Sprachmodellen zu erhalten, empfehlen wir folgende Publikationen:
- Schreibzentrum der Goethe-Universität Frankfurt a.M. (2023). Nutzung von KI-Schreibtools durch Studierende. https://www.starkerstart.uni-frankfurt.de/133460941.pdf
[letzter Zugriff: 13.08.2024]. - Albrecht, S. (2023). ChatGPT und andere Computermodell zur Sprachverarbeitung – Grundlagen, Anwendungspotenziale und mögliche Auswirkungen. Berlin: Büro für Technikfolgen-Abschätzung beim Deutschen Bundestag. https://publikationen.bibliothek.kit.edu/1000158070
[letzter Zugriff: 14.08.2024].
3.10 Ethische Aspekte und Gefahren von KI
3.10.1 Gefahren von Deep Learning
Die Verwendung von Texten in Sprachmodellen kann versteckte Gefahren mit sich bringen. Hier können auch Vorurteile reproduziert werden, die in einer Gesellschaft kursieren (siehe Einheit Medien.Identität). So assoziierten beispielsweise frühe Texte von GPT-3 (Generative Pre-Trained Transformer-3) Berufe mit höherem Bildungsniveau vermehrt mit Männern als mit Frauen. GPT-3 ist das Sprachmodell, das 2020 von OpenAI veröffentlicht wurde und 2022 dann für alle Interessierten einen öffentlichen Zugang ermöglicht hat. ChatGPT ist hingegen eine Anwendung davon, die auf die Fähigkeit des Modells zur Generierung von menschenähnlichem Text für Chatanwendungen abzielt. In Bezug auf die Verwendung von Stimmen kann die Macht der Künstlichen Intelligenz schnell für unlautere Zwecke missbraucht werden. Da Stimmmuster einzigartig sind, gelten sie in unserer Gesellschaft als weit verbreitetes Authentifizierungsmittel. Sehr häufig dienen sie auch als Beweismittel in Rechtsfällen. Mit der Möglichkeit, Stimmen identisch nachzuahmen (im Rahmen der Deep-Fake-Methode), könnten demnach Beweisstücke weitreichend manipuliert oder Sicherheitsvorkehrungen umgangen werden. Auch werden zunehmend Fälle von sogenannten ›Enkeltricks‹ bekannt, in denen Kriminelle sich als die Enkel*innen von Personen ausgeben und dafür ihre Stimme mit Hilfe Künstlicher Intelligenz exakt klonen können (vgl. Beuth 2023). Betrachtet man das Beispiel von Bildern, haben Personen des öffentlichen Lebens – wie andere auch – Rechte am eigenen Bild und können die kommerzielle Nutzung ihrer Bilder damit kontrollieren. Ähnlich ist es auch bei Charakteren oder Marken mit hohem Wiedererkennungswert, für die Urheberrechte oder Warenzeichen bestehen. Diese Bilder dürfen ohne Genehmigung des*r Rechteinhaber*in nicht verwendet werden. Wie KI-generierte Werke in Bezug auf das Urheberrecht behandelt werden, ist nicht abschließend geklärt. Das kann je nach Land und länderspezifischen Gesetzmäßigkeiten variieren.
3.10.2 Algorithmische Diskriminierung durch Digital Bias
Künstliche Intelligenz kann neben den bereits benannten Vorteilen in der Prozessoptimierung auch Herausforderungen durch diskriminierende Verhaltensweisen mit sich bringen. Algorithmen lernen von Daten, die nicht zwangsläufig vorurteilsfrei sind. Dies kann bewusst oder unbewusst passieren. Man spricht dann von Diskriminierung, wenn Entscheidungen von Merkmalen wie Geschlecht, Behinderung, Aussehen, Alter, Schwangerschaft oder Herkunft abhängig gemacht werden und dann entscheidend Einfluss auf z.B. die Arbeits-, Kreditvergabe o.Ä. nehmen (vgl. Hagendorff 2019; siehe auch Einheit Medien.Identität). In Bezug auf die Datenverarbeitung und Diskriminierung wird in zwei Bereiche unterschieden:
Die direkte Diskriminierung beschreibt Entscheidungen, die unmittelbar von sensiblen Informationen einer Person getroffen werden, z.B. von Geschlecht, Herkunft oder sexueller Orientierung.
Die indirekte Diskriminierung vollzieht sich anhand nicht sensibler Daten (z.B. der Postleitzahl), von denen aber auf sensible Daten indirekt geschlossen werden kann (durch die Postleitzahl kann z.B. auf das Viertel/den Stadtteil geschlossen werden, um so die soziale Herkunft abzuleiten).
Wenn Benachteiligungen in Daten vorhanden sind, lernen KI-Anwendungen diese und reproduzieren sie. Wenn Vorurteile in Datensätzen vorhanden sind oder marginalisierte Personengruppen unterrepräsentiert sind, spricht man von Bias (Verzerrung) (vgl. Poretschkin et al. 2021). Wie die Welt oder die Gesellschaft wahrgenommen wird, hängt oft von dem ab, was gelernt wird. Das ist geprägt durch die individuellen, sozialen, kulturellen oder ökonomischen Hintergründe. Diese wiederum sind geprägt von gesellschaftlichen Normen, familiärer Erziehung und Kulturangeboten sowie durch Einflüsse von Medien. Man unterscheidet daher mehrere Formen von Bias, auf denen Vorurteile basieren.
Menschen tendieren z.B. dazu, Informationen als vertrauenswürdig einzustufen, die ihrer bisherigen Meinung entsprechen oder ihr vorhandenes Wissen bestätigen. Diese Verhaltensweisen nennt man ›kognitiven Bias‹ (vgl. Poretschkin et al. 2021). Auf Grund der großen Datenmengen, die durch die tägliche Nutzung von Apps, dem Internet o.Ä. produziert und zur Verfügung gestellt werden, werden auch Meinungen oder Ansichten weitergegeben, die weitere Entscheidungen beeinflussen. Deshalb geht man davon aus, dass in Daten immer Bias existiert.
Wenn es zu Fehlern in der Datenerhebung kommt (z.B. durch fehlerhafte Verteilungen von Datenpunkten), kann dies zu fehlerhaften Ergebnissen in Untersuchungen führen. Beispielsweise kann die Art und Weise, wie ein Fragebogen aufgebaut ist, die Antwortangaben beeinflussen. Dann spricht man von einem ›statistischen Bias‹ (vgl. Poretschkin et al. 2021).
Wenn Algorithmen von einer gelernten Annahme aus vorhandenen Daten auf eine Verallgemeinerung schließen, nennt man das ›induktiven Bias‹ (vgl. Poretschkin et al. 2021). D.h., diese Daten können nicht frei von diskriminierenden Annahmen sein, da diese bereits in den Daten vorhanden sind. Als Beispiel kann hier aufgeführt werden, dass ursprünglich vermehrt Männer als Frauen in gewissen Berufen eingestellt wurden oder eine Beförderung erhalten haben und ein Algorithmus ausgehend von dieser Annahme eine verallgemeinernde Annahme bildet. Dann müsste man den Algorithmus explizit erlernen lassen, ob eine solche Annahme weiterhin legitim ist (vgl. Balkow/ Eckardt 2019).
3.11 Zwei Beispiele von Diskriminierung: Strafverfolgung und Bewerbungsprozesse
Wie man sich konkret diskriminierende Handlungen durch Daten bzw. Algorithmen vorstellen kann, lässt sich am besten anhand zweier Beispiele veranschaulichen.
Strafverfolgung: Ein bekanntes Beispiel ist das Redlining. Redlining beschreibt eine historische diskriminierende Praxis von Banken. In dieser ursprünglichen Praxis wurden Kredite nicht nach der Kreditwürdigkeit vergeben, sondern nach den Kriterien sozialer Herkunft, von denen vor allem marginalisierte Gruppen betroffen waren (vgl. Horwart 2022). Diese Praxis wird heute durch algorithmische Entscheidungen (algorithmisch generierte Credit Scores) fortgesetzt und als Technological Redlining bezeichnet. In diesem Vorgehen werden Punkte für die Kreditvergabe anhand bestimmter Kriterien vergeben. Diese Kriterien werden bspw. an Handlungsrisiken festgemacht, wie der Wahrscheinlichkeit, erneut straftätig zu werden. Für das beschriebene Vorgehen wurde eine bekannte Software namens COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) in den USA verwendet, die Berechnungen für eine Rückfallwahrscheinlichkeit anhand von Punktevergaben für straffällig gewordene Personen vornimmt. Anhand der Berechnungen wurde laut Studien schwarzen Männern im Vergleich zu weißen Männern ein höheres Risiko, rückfällig zu werden, zugeteilt. Daran lässt sich eine rassistische Praxis erkennen, die algorithmenbasiert vollzogen wird (vgl. Horwart 2022).
Bewerbungsprozesse: Ein zweites bekanntes Beispiel stellen Diskriminierungen durch Algorithmen von Softwareprogrammen in Bewerbungsprozessen dar. In dem Unternehmen Amazon, in dem die Personalverantwortlichen Bewerbungen mit Hilfe eines Algorithmus vorsortieren ließen, wurden Frauen im Vergleich zu männlichen Bewerbern systematisch schlechter bewertet. Das lag darin begründet, dass die Daten mit erfolgreichen Bewerbungen der vergangenen Jahre trainiert wurden, unter denen vorwiegend männliche Bewerber waren. Der Algorithmus hat damit das gelernte Wissen in Form von Stereotypen, die bereits in der Gesellschaft vorhanden waren, reproduziert (vgl. Hagendorff 2019).
- Wenn Algorithmen von Datensätzen lernen, die nicht vorurteilsfrei sind oder in denen marginalisierte Personengruppen unterrepräsentiert sind, reproduzieren sie diese Vorurteile. Dann spricht man von »algorithmischer Diskriminierung« oder »(Digital) Bias«. In Bezug auf Diskriminierung wird zwischen direkter und indirekter Diskriminierung unterschieden, auch in Bezug auf datenbasierte Diskriminierung. Man unterscheidet in mehrere Formen von Bias, auf denen Vorurteile basieren. Diese werden unterschieden in kognitivem, statistischem und induktivem Bias.
- Das Komplizierte an der datenbasierten Diskriminierung ist, dass durch die komplexe Datenverarbeitung eine Intransparenz in Bezug auf die Art und Weise der Diskriminierung herrscht.
Bearbeiten Sie die folgenden Aufgaben:
Für weitere Informationen zum Digital Bias von Computerprogrammen empfehlen wir eine Episode des Podcasts Feuer und Brot, in dem erläutert wird, welche Auswirkungen Künstliche Intelligenz auf marginalisierte Gruppen haben kann:
- Feuer & Brot (2020). Digital bias. Auch Computerprogramme können rassistisch sein feat. Nushin Yazdani. https://feuerundbrot.de/folgen/digitalbias
3.12 Ansätze gegen den Digital Bias
Es gibt mittlerweile Methoden, die versuchen, die computerbasierte Diskriminierung zu verhindern. Diese Methoden lassen sich in technische Verfahren und organisatorische Herangehensweisen unterteilen.
3.12.1 Technische Methoden im Maschinellen Lernen
Im Bereich der technischen Ansätze gibt es derweil einige Verfahren, die zur Verhinderung von algorithmischer Diskriminierung eingesetzt werden. Nachfolgend sollen zwei Beispiele aufgeführt werden, wie technische Modellierungen diesbezüglich aussehen könnten:
- Eine Methode technischer Art ist z.B. die Bereinigung von Daten mit Hilfe von Pre-processing Discrimination Prevention (Hagendorff 2019). D.h., dass Trainingsdaten gezielt ausgebessert werden, sodass Trainings für Algorithmen an bereinigten Daten bereitgestellt werden, um diese Diskriminierung möglichst zu verhindern. Am Beispiel des oben benannten Vorgehens der Bewerbungsprozesse würde der ursprünglich verwendete Lerndatensatz, der mehr männliche Bewerber beinhaltet, daraufhin geprüft und gezielt geändert werden.
- Eine weitere technische Methode nennt sich die Counterfactual Fairness (Joos/Meding 2022). Diese Methode beschreibt das Verändern von Merkmalen von z.B. Personen, um Diskriminierung zu verhindern. Hier wird bspw. geprüft, ob bei dem Geschlecht ›Frau‹ auch gleiche Ergebnisse erzielt werden wie bei dem Geschlecht ›Mann‹. Bleibt das Ergebnis gleich, so wird der Algorithmus als fair eingestuft.
3.12.2 Organisatorische Methoden im Maschinellen Lernen
Neben den mathematischen Verfahren gibt es auch organisatorische Entwicklungen als Ansätze gegen algorithmische Diskriminierung. In diesem Bereich gibt es deutlich weniger Methoden als bei den technischen. Auch hier werden beispielhaft nachfolgend zwei Ansätze vorgestellt:
- Eine antidiskriminierende Idee besteht darin, soziale Gerechtigkeit dadurch zu befördern, dass die Speicherung von Daten durch Organisationen gar nicht erst vorgenommen werden darf. D.h., die Speicherung personenbezogener Daten, die sensible Informationen über bspw. das Geschlecht, sexuelle Orientierung, Gesundheitszustand usw. preisgeben, könnte untersagt werden, sodass diese Informationen somit nicht für weitere datenbasierte Analysen verwendet werden können. Das Problem bei dieser Verfahrensweise ist jedoch, dass weiterhin die Möglichkeit der Diskriminierung besteht, die durch nicht sensible Informationen hervorgerufen werden kann (vgl. Hagendorff 2019).
- Ein anderer Vorschlag gestaltet sich durch das Heranziehen von Behörden oder Non-Government-Organisationen (Nichtregierungsorganisationen; NGOs) mit der Aufgabe, die Datenüberwachung bzw. Prüfung vorzunehmen. Bei diesem Vorgehen müsste noch differenziert werden, ob die herangezogenen Institutionen die Aufgabe haben, Diskriminierung nur aufzudecken oder auch präventiv tätig zu werden, um Bias gar nicht erst entstehen zu lassen. Diese Aufgaben würden ausgeprägte technische Expertise erfordern (vgl. Ebd.).
Das Fraunhofer-Institut hat einen Prüfkatalog erstellt, der einen Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz bietet. Dieser richtet sich an Entwickelnde und Prüfende und gibt einen Überblick über relevante Kriterien auch für Interessierte, die sich vertiefend in das Thema einlesen möchten:
- Frauenhofer IAIS (2021). Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz. KI-Prüfkatalog. https://www.iais.fraunhofer.de/de/forschung/kuenstliche-intelligenz/ki-pruefkatalog.html
[letzter Zugriff: 28.02.2025].
Dennoch bleibt festzuhalten, dass es keine universellen mathematischen oder organisatorischen Kriterien geben wird, um Diskriminierung durch Maschinelles Lernen zu verhindern. Faires Handeln muss situationsspezifisch und an Kontext und Zeit angepasst werden, um sozial gerechtes Handeln umzusetzen. Daher bleibt es ein wichtiges Anliegen für Programmierer*innen oder Softwareentwickler*innen, ihre Entwicklungen und Programmierungen an sozialen und kulturellen Kontexten festzumachen und diese als Grundlage für ihre Entscheidungen zu nehmen. Statistik allein wird keine Lösung bieten, um Diskriminierung zu verhindern. D.h., an dieser Stelle müssen mathematische und ethisch-soziale Kompetenzen gleichermaßen berücksichtigt werden (vgl. Hagendorff 2019).
Es gibt technische Methoden, die z.B. Datensätze bereinigen, um eine Reproduktion von datenbasierter Diskriminierung zu verhindern sowie organisatorische Methoden, bei denen z.B. sensible Daten gar nicht erst gespeichert werden. Dennoch gibt es keine universelle Formel (weder mathematisch noch organisatorisch), um Diskriminierung zu verhindern. In diesem Zusammenhang muss immer der soziale und kulturelle Kontext bedacht werden.
3.13 Gesetze zur Regulierung von Künstlicher Intelligenz
Im Mai 2024 wurde von der Europäischen Union das weltweit erste Gesetz zur Regulierung von KI eingeführt. Am 21. Mai 2024 wurde von dem Rat der 27 EU-Mitgliedstaaten der AI Act (Artificial Intelligence Act) verabschiedet, um damit einen einheitlichen gesetzlichen Rahmen für den Einsatz von Künstlicher Intelligenz in der Europäischen Union zu schaffen (vgl. Presse- und Informationsamt der Bundesregierung 2024).
Das Gesetz zur Regelung von Künstlicher Intelligenz legt fest, dass KI-Anwendungen nicht missbraucht werden dürfen. So soll der Schutz der Grundrechte gewährleistet werden. Das Gesetz verfolgt dabei einen sogenannten risikobasierten Ansatz. Das bedeutet, dass bei einer höheren Einschätzung des Risikos einer Anwendung strengere Vorgaben gelten. Ein nicht akzeptables Risiko stellen KI-Systeme dar, die ein Verhalten von Personen gezielt beeinflussen und manipulieren oder ein erwünschtes Verhalten anhand einer Vergabe von Punkten bewerten. Diese verbietet das neu geschaffene Gesetz. Zu dem Gesetz wurde eine Transparenzpflicht eingeführt. Somit müssen künstlich erzeugte oder bearbeitete Inhalte wie Audios, Bilder oder Videos klar gekennzeichnet werden. Außerdem müssen hochriskante KI-Systeme, die den Bereichen der kritischen Infrastruktur, Beschäftigung sowie Gesundheits- oder Bankenwesen betreffen, bestimmte Anforderungen erfüllen, um zugelassen zu werden (vgl. Presse- und Informationsamt der Bundesregierung 2024).
Weitere Informationen zu dem ersten KI-Gesetz können auf folgenden Seiten nachgelesen werden:
- Europäisches Parlament (2024). Gesetz über künstliche Intelligenz: Parlament verabschiedet wegweisende Regeln, [online], Aktuelles Europäisches Parlament. https://www.europarl.europa.eu/news/de/press-room/20240308IPR19015/gesetz-uber-kunstliche-intelligenz-parlament-verabschiedet-wegweisende-regeln
[letzter Zugriff: 13.08.2024]. - Bundesministerium für Digitales und Verkehr (2024). Erstes KI-Gesetz der Welt verabschiedet, [online], Bundesministerium für Digitales und Verkehr. https://bmdv.bund.de/SharedDocs/DE/Artikel/K/erstes-ki-gesetz.html
[letzter Zugriff: 13.08.2024].
3.14 Social Media und Algorithmen: Das Beispiel TikTok
Social Media sind allgegenwärtig und nicht mehr aus unserem Alltag wegzudenken. Erst waren es Facebook und Instagram, die ein rasantes Wachstum an Popularität gewonnen haben. Heute ist es unter anderen Social-Media-Plattformen auch TikTok. TikTok ist eine App, auf der viele kurze Videos schnell hintereinander gezeigt werden und nur wenige Sekunden oder Minuten dauern. Die Videos beinhalten thematisch eine Vielzahl abbildbarer Inhalte: Kochanleitungen, lustige Inhalte bis hin zu politischen Themen. Dass die App so ein rasantes Wachstum erfahren hat, liegt vor allem an dem Algorithmus. Denn die Qualität der Algorithmen wurde in den letzten Jahren derart verbessert, dass die Videos immer mehr den Interessen der Nutzer*innen entsprechend angezeigt werden. Dadurch schafft die App eine immer längere und häufigere Bindung an das Gerät. Anders als beim Algorithmus von Instagram verwendet TikTok eine Gewichtung durch die Engagement Rate (vgl. Sbai 2021). Die Engagement Rate ist der Prozentsatz des Publikums, der die Beiträge liket, kommentiert oder teilt. Lange Zeit blieb der Algorithmus von TikTok ein großes Geheimnis. Das Unternehmen hat sich aber auf Grund großer Kritik und im Sinne einer Transparenz dazu entschieden, über seine eigene Website Informationen zum Algorithmus zu veröffentlichen (vgl. Sbai 2021). Laut TikTok entscheidet der Algorithmus über die Beliebtheit der Videos anhand folgender Kriterien:
- Die Menge der Kommentare, die von Nutzer*innen gepostet werden.
- Die Menge an Accounts, denen Nutzer*innen folgen.
- Die Kombination aus eigenen Interessen, die man zum Ausdruck bringt und dem, was einen nicht interessiert.
- Interaktionen wie das Liken von Videos oder das Teilen von Videos.
- Videoinformationen wie z.B. Hashtags, Musik und Bildunterschriften.
- Einstellungen zum Account, wie die Sprache, das Land oder das verwendete Gerät.
Dabei spielt es z.B. bei der Gewichtung eine Rolle, ob ein Video ganz angesehen wird oder nach wenigen Sekunden gestoppt wird. Die App verwendet verschiedene Mittel, um sich interessant zu halten und die Nutzer*innen an sich zu binden (vgl. Sbai 2021). Darunter fällt z.B. das Teasern. In einem Teaser wird das Ende eines selbst erstellten Videos bewusst offengelassen. Die Community wird anschließend gefragt, einen zweiten Teil des Videos zu erstellen, und meist wird dafür ein bestimmtes Datum festgelegt. Dadurch werden Anreize für Nutzer*innen gesetzt, weitere Videos zu erstellen. Auch besteht die Möglichkeit, durch die Creator Mentions Personen in Kommentaren zu erwähnen, (auch ›taggen‹ genannt), wenn ein veröffentlichtes Video bspw. von anderen inspiriert wurde oder andere Personen in dem Video vorkommen. Dadurch können die Personen, die als Inspiration genutzt werden oder in den Videos vorkommen, durch die Erwähnung auf der Plattform TikTok bekannter gemacht werden. Auch Shout Outs werden als Methode verwendet. Das funktioniert so, dass ein Accountname oder ein Link eines Accounts in einem von sich selbst erstellten Beitrag eingefügt wird (tagging). Häufig wird die Funktion genutzt, um einen Satz zu beginnen, in dem ein Shout Out angekündigt wird (z.B. »Shout Out an alle Leute, die gerade dieses Video sehen« o.ä.). Auch beliebt ist die Funktion der Hashtag Challenges. Damit können unter einem bestimmten Hashtag Wettbewerbe von Nutzer*innen organisiert werden, an denen sich andere beteiligen können. Das funktioniert bspw., indem ein Video zu einem bestimmten Thema oder einer Aufgabe bereitgestellt wird und Nutzer*innen darin aufgefordert werden, das Thema oder die Aufgabe nachzustellen (vgl. Sbai 2021). Damit beteiligen sie sich an dem Wettbewerb und die Reichweite wird erhöht. Auch Unternehmen nutzen diese Funktion bereits für Werbezwecke, um viele Personen zu erreichen und für ihr Unternehmen zu werben. Wenn Unternehmen einen Wettbewerb initiieren, wird das Branded Hashtag Challenge genannt. Diese werden dann auch professionell von Agenturen umgesetzt. Diese Wettbewerbe helfen dem Algorithmus, zu identifizieren, welche Personen die Inhalte ansprechen.
Social-Media-Plattformen wie TikTok liefern den Nutzer*innen auf sie zugeschnittene Inhalte. Gleichzeitig schirmen sie andere Meinungen ab, die nicht ihren Interessen entsprechen (vgl. Menczer/Hills 2021). Diese Art der Vorsortierung von Inhalten kann gefährlich sein und dazu beitragen, dass gewisse Meinungen und Überzeugungen sich verfestigen und keine anderen Sichtweisen zugelassen werden (siehe Einheit Medien.Identität). Untersuchungen zeigen auf, dass Menschen oft nach einer Bestätigung ihrer Meinung suchen und jenes Verhalten durch den Algorithmus perfektioniert wird (vgl. Menczer/Hills 2021). Social Media verwenden z.T. auch automatisierte Bots, um bestimmte Inhalte zu streuen und die Qualität von Informationen zu verändern, indem bspw. Fehlinformationen verbreitet werden. Diese Bots sind technisch leicht zu entwickeln und tragen in hohem Maße mit falschen Profilen und Informationen dazu bei, dass falsche Meldungen in Umlauf gebracht werden. Nach Schätzungen von Expert*innen wurden diese z.B. vielfach im Jahr 2016 bei der US-Wahl eingesetzt, um binnen Sekunden tausende falsche Nachrichten in die Feeds (Hauptseite einer Social-Media-Seite) der Nutzer*innen zu verbreiten und so die politische Meinung von Menschen zu manipulieren. Die Informationen der Bots werden durch Menschen geteilt, woraus eine schnelle Verbreitung resultiert. So verharren Personen in ihren Filterblasen, da diese durch den Algorithmus verstärkt werden (vgl. Menczer/Hills 2021).
Die Nutzung von Social Media steht auch eng im Zusammenhang mit digitalen Ungleichheiten. Ungleichheiten bestehen in Bezug auf einen Zugang (auch First-level Digital Divide genannt), auf die Nutzungsweisen (auch als Second-level Divide beschrieben) sowie infrastrukturelle Ungleichheiten (auch als Third-level Divide) (vgl. Verständig et al. 2016). Letzteres bezieht sich auf die Architektur und die Strukturen von Softwareprogrammen und Apps sowie die des Internets. Dabei handelt es sich bei der Infrastruktur um die Übermittlung von Datenpaketen, die grundlegend als neutral konzipiert sind. Dennoch gibt es technisch betrachtet Verfahren, die Datenpakete nicht neutral vermitteln, sondern nach Inhalten priorisieren (u.a. Deep-Packet Inspection). Die inhaltlichen Priorisierungen basieren auf diskriminierenden Unterscheidungen. Das lässt sich am besten am Beispiel der zuvor beschriebenen Filterblasen erklären, die auf einer Analyse von Suchanfragen beruhen, sowie auf zukünftigen Priorisierungen von Filtern der Suchergebnisse. Daraufhin entstehen die sogenannten ›Blasen‹, die personalisierte Inhalte anzeigen. Die Ungleichheiten beruhen darauf, dass die technische Infrastruktur vorbestimmt, wer sich z.B. Gehör auf den Social-Media-Plattformen wie TikTok verschaffen kann (vgl. Verständig et al. 2016).
Im Jahr 2020 gab es einen Diskriminierungsskandal um den Algorithmus von TikTok. Durch den Algorithmus erhielten die Videos bestimmter Personengruppen weniger Reichweite als die von anderen. Wir empfehlen diesen Artikel als Vertiefung zu diesem Thema:
- Sippel, S. (2020). Diskriminierung bei »Tiktok«: »Hässliche« Menschen?, FAZ online, [online] https://www.faz.net/aktuell/feuilleton/medien/diskriminierung-tiktok-betreibt-selektion-16685047.html
[letzter Zugriff: 14.08.2024].
3.15 Wie kann man sich vor Manipulation durch Algorithmen schützen?
Um einer Manipulation von Algorithmen zu entgehen, ist es wichtig, diese zu verstehen. Dazu wurden einige Tools entwickelt, die die Verhaltensweisen von Algorithmen simulieren, um sie nachvollziehbar zu machen (vgl. Menczer/Hills 2021). Diese werden nachfolgend aufgeführt:
- Mit der App Fakey können Nutzer*innen Inhalte auf ihren Wahrheitsgehalt prüfen und lernen, falsche Informationen von richtigen zu unterscheiden.
- Das Programm Hoaxy zeigt durch eine Simulation die Verbreitungsprozesse von Tweets auf der Plattform X (ehemals Twitter). Hier wird auch anschaulich visualisiert, wie Bots zur Verbreitung von Fake News
beitragen. - Die Software BotSlayer ist in der Lage, anhand von Hashtags, Links, Inhalten usw. Profile zu identifizieren, die populär sind und mit hoher Wahrscheinlichkeit durch Bots verstärkt werden. Damit sollen gefälschte politische Kampagnen aufgedeckt werden.
Die Algorithmen von Social Media (wie bspw. von TikTok) entscheiden darüber, welche Inhalte den Nutzer*innen angezeigt werden und welche ausgeblendet werden. Dadurch entstehen gefährliche Filterblasen, in denen nur noch das eigene Interesse bzw. die eigene Meinung reproduziert wird, z.B. durch personalisierte Werbung, die auf die eigenen Interessen zugeschnitten angezeigt wird.
Wir nähern uns im nachfolgenden Abschnitt dem Themenfeld der Datenkompetenz. Was verstehen Sie unter dem Begriff ›Datenkompetenz‹? Welche Aspekte würden Sie darunter erfassen, die den Begriff für Sie erklären?
3.16 Datenkompetenz – Data Literacy
Wie bereits in der Orientierung formuliert, soll in diesem Abschnitt ein Bewusstsein für die Nutzung und Verarbeitung von Daten geschaffen werden. In diesem Zusammenhang ist eine Datenkompetenz – auch häufig mit dem Begriff Data Literacy aufgeführt – von Relevanz. Daher soll dieser Begriff nun näher erläutert werden.
Data Literacy wird bereits von Expert*innen als eine der relevantesten Future Skills der gegenwärtigen Zeit aufgeführt (vgl. Ehlers 2020). Digitale Technologien sind ein wichtiges Mittel, um Wissen über die Verarbeitung und Bewertung von Informationen sowie Wissen über Kommunikation oder politische wie auch gesellschaftliche Partizipation zu erwerben. Dazu müssen Kompetenzen, die den Wissensaufbau bis hin zu Anwendungskenntnissen über Technik (siehe nachfolgender Abschnitt »Kategorisierung von Datenkompetenz«) umfassen, mit digitalen Technologien entwickelt und gefördert werden. Wenn von diesen sogenannten »digitalen Kompetenzen« gesprochen wird, sind ganz vielfältige Aspekte gemeint. Die Bandbreite der Medienkompetenz oder der digitalen Kompetenz (siehe Einheit Medien.Didaktik) reicht von der Fähigkeit, Quellen zu bewerten, über die Kompetenz in der digitalen Welt respektvoll zu kommunizieren, bis hin zu der Kompetenz, Funktionsweisen von Software und Hardware zu kennen. Darüber hinaus umfasst sie zudem das Wissen über Geschäftsmodelle von Informations- und Kommunikationsdiensten, um Verhaltensweisen und mögliche Konsequenzen angemessen zu reflektieren (vgl. Nationale Akademie der Wissenschaften Leopoldina (2021). Ebenfalls braucht es – und diese Kompetenz will die vorliegende Einheit adressieren – die sogenannte ›Datenkompetenz‹ (Data Literacy). Jene Kompetenz wird bereits unter den Schlüsselkompetenzen für das 21. Jahrhundert (siehe Einheit Medien.Begriffe) gelistet, mit der Idee, der stetig wachsenden Menge an Daten, dem Management und der Bewertung und Anwendung dieser gerecht zu werden (vgl. Ludwig/Thiemann 2020). In diesem Zusammenhang wird folgendes Wissen relevant (vgl. Nationale Akademie der Wissenschaften Leopoldina 2021):
- Informatisches und technisches Wissen umfasst bspw. die Nutzung von Datenbanken oder die Entwicklung von Software.
- Mathematisches Wissen schließt z.B. das Fachgebiet Statistik und Wahrscheinlichkeitstheorie ein.
- Empirische Kenntnisse beschreiben das Wissen darüber, wie man wissenschaftliche Erkenntnisse gewinnt.
- Kontextwissen wird im Zusammenhang mit sozialem oder kulturellem Wissen relevant.
3.17 Kategorisierung von Datenkompetenz
Um den sehr vagen Begriff ›Datenkompetenz‹ nun näher zu verstehen, stellt das Hochschulforum Digitalisierung einzelne Bereiche vor, die den Begriff weiter unterteilen (vgl. Schüller et al. 2019):
- Konzeptioneller Rahmen: Darunter wird der Aufbau von Wissen über Daten und das Verständnis von Daten erfasst. Das dient in erster Linie dazu, ein generelles Verständnis für die Nutzung und Anwendung von Daten zu bekommen
- Datensammlung: Die Datensammlung beschreibt eine Erfassung von Daten aus diversen Quellen (z.B. aus Social Media oder technischen Simulationen). Anschließend müssen die Datenquellen hinsichtlich der Zuverlässigkeit und Qualität kritisch bewertet werden.
- Datenmanagement: In diesem Kompetenzbereich werden die Daten verwaltet, indem Unregelmäßigkeiten ausradiert werden und anschließend als Datensätze zusammengeführt und ggf. in andere Formate konvertiert werden. In diesem Schritt werden auch die Datenspeicherung und Archivierung relevant. Im Weiteren erfolgt die Festlegung von Bedingungen für Datenobjekte (Annotation) mit Metadaten (Informationen von Daten über andere Daten), um diese für einen späteren Zeitpunkt verwertbar zu machen.
- Datenevaluation: Die Evaluation umfasst die numerische sowie grafische Auswertung der vorliegenden Daten. In einem weiteren Schritt werden die Daten interpretiert.
- Datenanwendung: Dieser Bereich befasst sich mit ethischen Fragen und der Verteilung und Evaluierung von datenbasierten Entscheidungen.
Die Einordnung von Datenkompetenz in diese fünf zuvor genannten Kategorisierungen kann für verschiedene Anwendungsgebiete verwendet werden. Somit lassen sich je nach Fachgebiet für verschiedene Kompetenzbereiche entsprechende Lernziele und Lerninhalte formulieren, die in der Schule, Berufsschule, Hochschule oder anderen Bildungsinstitutionen Anwendung finden (vgl. Ludwig/Thiemann 2020).
Bearbeiten Sie die folgende Aufgaben:
Weiterführende Lernangebote vom KI-Campus zu Datenkompetenz finden sich in folgenden Lernkursen:
- »Von der Datenanalyse zur Datengeschichte«: https://ki-campus.org/node/758
- »Schule macht Daten«: https://ki-campus.org/courses/datenschule
- »KI als Werkzeug in der beruflichen Bildung«: https://ki-campus.org/courses/aivet-um-III-2021
- »Big Data Analytics«: https://ki-campus.org/courses/bigdata2017
- »Entscheidungsbäume do it yourself (DIY) – Datenbasiertes Entscheiden«: https://ki-campus.org/courses/baeumediy-upb2021
3.18 Fazit
Künstliche Intelligenz bietet mit all ihren Facetten viele neue Anwendungsfelder und Möglichkeiten technischer Neuerungen und innovativer Programme. Einige davon wurden in dieser Einheit vorgestellt. Dennoch werfen neue technologische Entwicklungen auch ethische Bedenken und Debatten auf. Die Sorge, eine Künstliche Intelligenz würde zu mächtig werden und sich über die Menschheit stellen, ist in der Gesellschaft vorhanden. Diese Angst wird nicht zuletzt durch futuristische Filme befeuert. Bisher können algorithmische Systeme lediglich durch zuvor von Menschen definierte Probleme lösen im Sinne einer schwachen Künstlichen Intelligenz. Sie sind aber technisch nicht in der Lage, ein Anwendungsgebiet selbstständig zu erweitern und eigenmächtig zu handeln (vgl. Buxmann/Schmidt 2021). Wichtig ist anzumerken, dass jede Person selbst gefragt ist, sich gegen Unsicherheiten bzw. Unwissen zu schützen. Daher ist das Wissen über Daten unabdingbar und Anwendungen sollten stets kritisch hinterfragt werden.
3.19 Verwendete Quellen
Aust, H. (2021). Das Zeitalter der Daten. Was Sie über Grundlagen, Algorithmen und Anwendungen sollten. Berlin: Springer.
Balkow, C./Eckardt, I. (2019). Denkimpuls digitale Ethik. Bias in algorithmischen Systemen –Erläuterungen, Beispiele und Thesen. Berlin: Initiative D21 e.V. https://initiatived21.de/app/uploads/2019/03/algomon_denkimpuls_bias_190318.pdf
Beuth, P. (2023). Wie der Enkeltrick dank KI noch schäbiger wird. In: Spiegel online, [online], https://www.spiegel.de/netzwelt/web/enkeltrick-dank-kuenstlicher-intelligenz-jetzt-noch-schaebiger-a-7926b42d-7f3f-4a66-9aa4-2f2a82e7e771
Buxmann, P./ Schmidt, H. (2021). Ethische Aspekte der Künstlichen Intelligenz. In: Buxmann, P./ Schmidt, H. (Hg.), Künstliche Intelligenz, Berlin/Heidelberg: Springer Gabler. https://doi.org/10.1007/978-3-662-61794-6_13
De Witt, C. de/Rampelt, F./Pinkwart, N. (2020). Künstliche Intelligenz in der Hochschulbildung. Whitepaper. Berlin: KI-Campus.
Ehlers, U. D. (2020). Theoretische Grundlagen für Future Skills oder die »Drift to Self-Organisation«. In: Future Skills. Zukunft der Hochschulbildung – Future Higher Education. Wiesbaden: Springer VS. 127-158. https://doi.org/10.1007/978-3-658-29297-3_8
Fink, M.A. (2023). Große Sprachmodelle wie ChatGPT und GPT-4 für eine patientenzentrierte Radiologie. In: Die Radiologie 63, 665-671.
Fjelland, R. (2020). Why General Artificial Intelligence will not be Realized. In: Humanities and Social Sciences Communications 7(10), 1-9. https://doi.org/10.1057/s41599-020-0494-4
Hagendorff, T. (2019). Maschinelles Lernen und Diskriminierung: Probleme und Lösungsansätze. In: Österreichische Zeitschrift für Soziologie 44 (S1), 53-66. https://doi.org/10.1007/s11614-019-00347-2
Horwath, I. (2022). Algorithmen, KI und soziale Diskriminierung In: Schnegg, K. et al. (Hg.), Inter- und multidisziplinäre Perspektiven der Geschlechterforschung. (1. Auflage). Innsbruck: Innsbruck University Press.
Hummel, P. (2017). Die Tücken der Gesichtserkennung. In: Spektrum.de, [online], https://www.spektrum.de/news/die-tuecken-der-gesichtserkennung/1521469
Irmler, M. (2023). Künstliche Intelligenz in der Pflege. In: Heilberufe 75(4), 44-47.
Jones, N. (2014). Wie Maschinen lernen. In: Nature 505, 146-148.
Joos, D./ Meding, K. (2022). Anforderungen bei der Einführung und Entwicklung von KI zur Gewährleistung von Fairness und Diskriminierungsfreiheit. In: Datenschutz und Datensicherheit 46, 376-380. https://doi.org/10.1007/s11623-022-1623-6
Kalla, D./ Smith, N. (2023). Study and Analysis of Chat GPT and its Impact on Different Fields of Study. In: International Journal of Innovative Science and Research Technology 8(3), 827-833. https://ssrn.com/abstract=4402499
Kaur, S./ Kumar, P./ Kumaraguru, P. (2020). Deepfakes: Temporal Sequential Analysis to Detect Face-swapped Video Clips Using Convolutional Long Short-term Memory. In: Journal of Electronic Imaging 29(3
Kulyk, O./ Gerber, N./ Volkamer, M./Hilt, A. (2019). Wahrnehmungen und Reaktionen der Endnutzer auf Cookie-Meldungen. In: Datenschutz und Datensicherheit 43, 81-85. https://doi.org/10.1007/s11623-019-1068-8
Levermann, T. (2018). Wie Algorithmen eine Kultur der Digitalität konstituieren: Über die kulturelle Wirkmacht automatisierter Handlungsanweisungen in der Infosphäre. In: Journal für korporative Kommunikation 2, 31-42. https://nbn-resolving.org/urn:nbn:de:0168-ssoar-62401-9
Ludwig, T./ Thiemann, H. (2020). Datenkompetenz – Data Literacy. In: Informatik Spektrum 43, 436-439. https://doi.org/10.1007/s00287-020-01320-0
Mah, D.-K./Rampelt, F./Dufentester, C./Bernd, M./Gamst, C./Weygandt, B. (2020).
Digitale Lernangebote zum Thema Künstliche Intelligenz. Überblicksstudie zu kostenlosen
Online-Kursen auf deutschen Lernplattformen. Berlin: KI-Campus. https://doi.org/10.5281/zenodo.4293318
Mania, H. (2021). Die Digitalisierung verändert (auch) die Pflege. Pflegezeitschrift 74, 10-12. https://doi.org/10.1007/s41906-021-1150-3
Menczer, F./Hills, T. (2021). Algorithmen: Die digitale Manipulation. In: Spektrum.de, [online], https://www.spektrum.de/news/wie-algorithmen-uns-manipulieren/1849438
Mockenhaupt, A./Schlagenhauf, T. (2024). Maschinelles Lernen. In: Digitalisierung und Künstliche Intelligenz in der Produktion. Wiesbaden: Springer Vieweg. https://doi.org/10.1007/978-3-658-41935-6_6
Mustak, M./Salminen, J./ Mäntymäki, M./ Rahman, A./ Dwivedi, Y. K. (2023). Deepfakes: Deceptions, mitigations, and opportunities. In: Journal of Business Research 154, 113-368.
Nationale Akademie der Wissenschaften Leopoldina (2021). Digitalisierung und Demokratie. https://levana.leopoldina.org/servlets/MCRFileNodeServlet/leopoldina_derivate_00199/2021_Leopoldina_
Stellungnahme_Digitalisierung_Demokratie_de.pdf
Orwat, C. (2019). Diskriminierungsrisiken durch Verwendung von Algorithmen: Eine Studie, erstellt mit einer Zuwendung der Antidiskriminierungsstelle des Bundes. Baden-Baden: Nomos.
Poretschkin, M. et al./Fraunhofer IAIS (2021). Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz. KI-Prüfkatalog, [online], https://www.iais.fraunhofer.de/de/forschung/kuenstliche-intelligenz/ki-pruefkatalog.html
Presse- und Informationsamt der Bundesregierung (2024). Einheitliche Regeln für Künstliche Intelligenz in der EU. https://www.bundesregierung.de/breg-de/themen/digitalisierung/kuenstliche-intelligenz/ai-act-2285944
Sbai, A. (2021). TikTok – der neue Stern am Social-Media-Himmel. In: Jahnke, M. (Hg.), Influencer Marketing: Für Unternehmen und Influencer: Strategien, Erfolgsfaktoren, Instrumente, rechtlicher Rahmen. Mit vielen Beispielen. Wiesbaden: Springer Gabler, 95-126.
Schüller, K./Busch, P./Hindinger, C. (2019). Future Skills: Ein Framework für Data Literacy – Kompetenzrahmen und Forschungsbericht. Arbeitspapier Nr. 47. Berlin: Hochschulforum Digitalisierung. https://doi.org/10.5281/zenodo.3349865
Verständig D./Klein A./Iske S. (2016). Zero-Level Digital Divide: neues Netz und neue Ungleichheiten. In: Siegen: sozial – Analysen, Berichte, Kontroversen 21(1), 50-55.