Text: Medien.Daten
3.6 Deep Learning als Teilbereich des Maschinellen Lernens
Deep Learning stellt eine Methode zur Informationsverarbeitung dar und zählt zu den Teilbereichen des Maschinellen Lernens und Künstlicher Intelligenz.
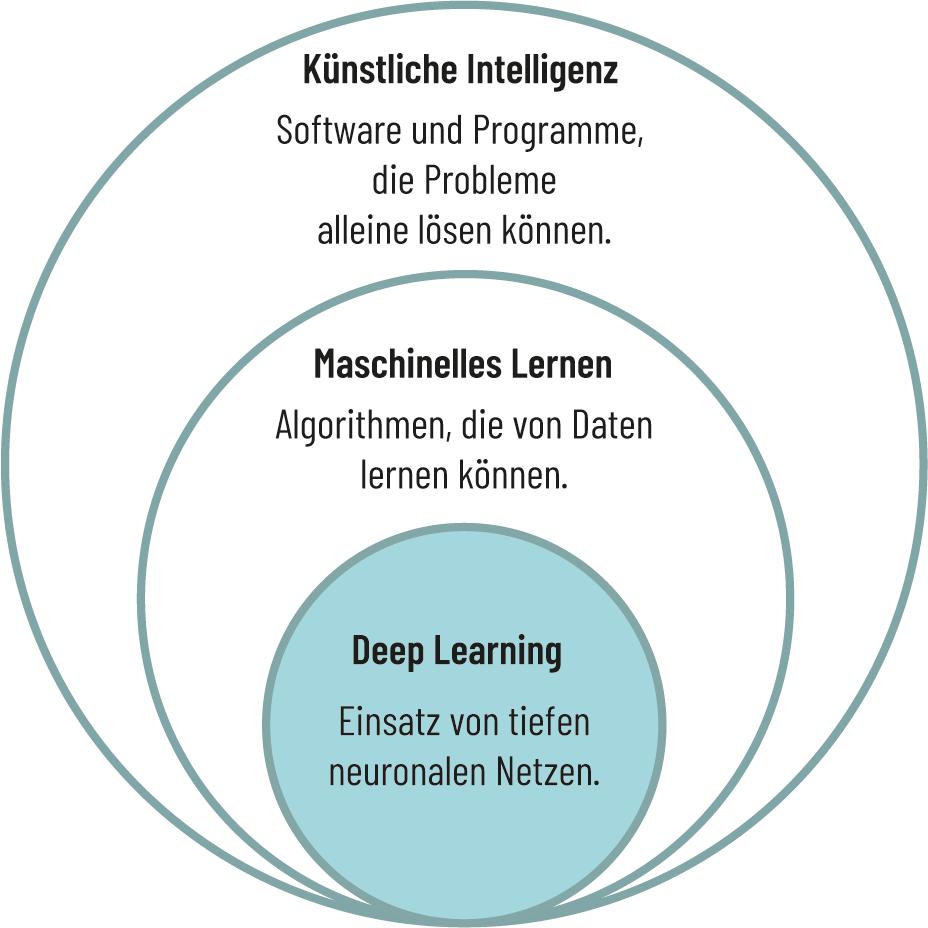
Abb. 3.5: Deep Learning als Teilbereich des Maschinellen Lernens.
Quelle: Eigene Darstellung angelehnt an datasolut 2023.
Das Deep Learning verwendet künstliche neuronale Netzwerke für die Analyse großer Datenmengen, die ähnlich wie unser Gehirn aus Erfahrungen lernen. Diese neuronalen Netzwerke stellen Algorithmen dar, die nach einer ähnlichen Struktur wie ein Gehirn aufgebaut werden (vgl. Aust 2021). Diese Methode der Informationsverarbeitung ermöglicht es einem System, eigene Entscheidungen zu treffen. Dazu muss ein Deep-Learning-Algorithmus, wie andere Algorithmen, zunächst entsprechend trainiert werden. Die Deep-Learning-Algorithmen können im Zuge einer erneuten Überprüfung anschließend noch einmal bestätigt oder geändert werden. Der Unterschied der Deep-Learning-Algorithmen im Vergleich zu den Algorithmen des Maschinellen Lernens liegt darin, dass die Deep-Learning-Algorithmen durch die Verwendung der neuronalen Netzwerke auch in unstrukturierten Informationen (Texte, Bilder, Töne usw.) Merkmale erkennen und numerische Werte zuordnen können. Anhand dieser Mustererkennung können die Algorithmen weiterarbeiten und weiterlernen (vgl. Aust 2021).
Algorithmen des Maschinellen Lernens hingegen nutzen keine neuronalen Netzwerke und können damit unstrukturierte Daten nicht sinnvoll weiterverarbeiten. Sie benötigen strukturierte Informationen, z.B. Werte aus einer Excel-Tabelle oder Datensätze einer Datenbank. Würde man dem Algorithmus des Maschinellen Lernens Katzenbilder präsentieren, müssten vorab spezifische Merkmale (Gesichtsform, Ohren, Farbe usw.) definiert werden. D.h., dass keine einfachen Bilder zur Datenverarbeitung genutzt werden können, sondern ein aufwendiges Feature Engineering (ein Prozess, in dem Rohdaten in Merkmale umgewandelt werden) durch den Menschen, wie am Beispiel der Katzenbilder erklärt, eingegeben werden müsste (vgl. Aust 2021). Die Algorithmen des Deep Learning hingegen benötigen diesen aufwendigen Prozess der Merkmalszuordnung vorab nicht. Sie können bei den Katzenbildern bspw. eigenständig Merkmale erkennen und zuordnen. Somit müssen diese Algorithmen zwar auch angelernt werden, aber weitaus weniger aufwendig. Das neuronale Netzwerk des Deep Learning arbeitet auf verschiedenen Ebenen. Am Beispiel der Bilderkennung lässt es sich wie folgt veranschaulichen: Ebene 1 erkennt die Helligkeit der einzelnen Pixel (Bildpunkte). Ebene 2 erkennt als Linie zusammenhängende Pixel. Ebene 3 erkennt den Unterschied zwischen horizontalen, vertikalen und diagonalen Linien. Auf der letzten Ebene schließlich erkennt das System z.B. das Foto einer Straße, das auf Grund vieler ähnlicher Bilder in eine Kategorie sortiert werden kann (vgl. Jones 2014).

Abb. 3.6: Die Ebenen des neuronalen Netzwerkes des Deep Learning.
Quelle: © Jones, N.: Computer science: The learning machines. Nature 505, 2014; Einzelbilder: Andrew Ng, Stanford Artificial Intelligence Lab (Ausschnitt).